I have recently been intrigued about the evolving science of social network analysis (SNA) and the potential novel yet practical applications of it in growing businesses. So the timing of the 3rd Annual Stanford Conference on Computational Social Science, hosted by IRiSS could not have been better.
Fun day with very cool thoughts, from the keynote of the superstar in the field, Duncan “small worlds” Watts to very practical insights from Facebook and Google scientists to usage of SNA on unusual datasets such as the englightement-era snail mail metadata (who was the bridging node between Voltaire and Ben Franklin?) to the intricacies of linguistic change (“aroma” getting replaced by “smell”) in beer enthusiast forums.
Some assorted notes and further reading links are below.
Duncan Watts: Principal Researcher at Microsoft Research NYC, Presenting: Computational Social Science: Exciting Progress and Grand Challenges
- Duncan’s small-worlds article_ is the 5th most cited one in Nature _
- Micro-macro problem in social science research: in order to do any macro scale experiments, you need to amass more than feasible amount of micro level data about individuals, even with modest population sizes
- Root cause of so many theories in social sciences without scientific experiments to back them
- Web is the beginning of getting over these barriers
- Rise of Computational Social Science (Lazer et al 2009)
- Social Contagion research to date
- 2 fundamental questions
- Why do some things succeed and not others?
- What is the dynamics of success?
- Many models: “disease” (Bass, 1969), “threshold” (Granovetter, 1978), “Learning” (1992), “Cascade” (Kleinberg & Kempe, 2003)
- “Going viral” implies large, multi-step, peer to peer contagion.
- Models vs Data problems
- S-shaped adoption curves could result from many processes (population heterogeneity, marketing efforts, …)
- Data is only collected on successful diffusion (in reality many fail)
- 2 fundamental questions
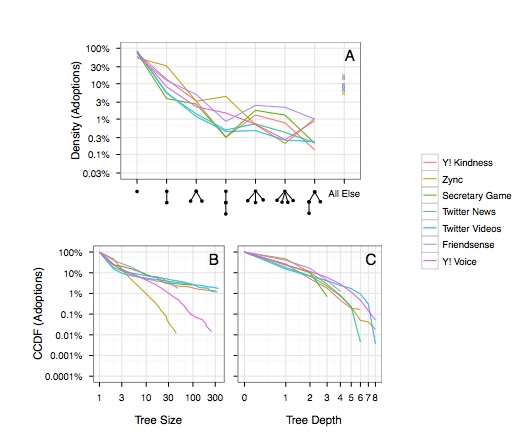
- How Much Adoption is Viral: The Structure of Online Diffusion Networks (Goel, Watts, Goldstein 2012 – PDF),
- Looking at 6 different web products, with different networks, inference procedures, success rates
- Reason to believe any emerging patterns are robust – and there is tremendous commonality: out of 30 possible patterns suspected only 7 appeared
- 90% adoptions are direct from the source
- 99% of adoptions are 1 hop from the source
- “Buzz Kill Law”of Social Media
- In reaction to criticism to above looking just at “non-performing products”, a study looking only at very popular stuff (Goel et al 2013)
- scanned 1.4B tweets & retweets for photos, news bits, videos, etc shared at least 100 times
- looked for viral spreading and just broadcasting patterns – results were all over the place, no dominating patter
- Work suggests theoretical insights:
- Analogy of “social epidemics” (including a tipping point as an epidemic threshold!) is misleading
- Most adoptions happen close to seed (die out rapidly)
- only exception is Justin Bieber running a scale free, enormously skewed network – basically behaving like old-school broadcast
- Big Data problems for social sciences
- difficult to infer causality
- rarely generated with social science question in mind – may not answer the question of interest
- typically a proxy for actual quality of interest (influence VS retweets, relationships VS emails). For example a graph built on people who have sent 2 emails in last week to each other is vastly different in properties from “2 emails in last year”.
- Replication of Milgram’s original “six degrees of separation” experiment over email (Dodds et al 2003)
- Raw number of chains was 4, but if you correct for attrition in median change lengths, you still get to Milgram’s 7
- Discovery of “bored at work” network – millions of people in the world sitting in the office bored and willing to help social science experiments if they are just marginally more interesting than what they’re supposed to do… 🙂
- Music Lab experiment for social influence and market dynamics, 14000 participants chose between 48 unknown songs (Salganik, Dodds, Watts, Science, 2006)
- When people see what others like, these things become more popular
- Yet, _what_ becomes popular is increasingly hard to predict
- Where next?
- Big problems of social science not being solved: financial market incentives, wealth gaps, organisational performance, political conflicts, …
- Science needs “social supercollider” that consolidates the fractured data — tons on legal, ethical, privacy issues to solve first
- Putting “an army in the virtual lab” – Amazon Mechanical Turk has a 3K user base turning over in a few months, not fit to run experiments for millions over years
Dan Edelstein: Professor of French and, by courtesy, History, Stanford University, Presenting: From Gutenberg to Zuckerberg: Social Media in the Enlightenment
Digital humanities – using computational methods to answer questions about humanities (and raise new ones)
- Mapping the Republic of Letters project
- http://knot-dev.herokuapp.com/investigate.html – try playing around in Voltaire’s network
Ed H. Chi: Staff Research Scientist, Google, Presenting: The Science of Social Interactions on the Web
- Exponential Growth Model is so commonplace & recurring (library of congress, wikipedia, academic articles) that data scientists just take note of it and move on
- Wikipedia still grows exponentially the number of articles… but the number of unique editors flatlined in 2007 – why?
- If you apply the logistic growth model (aka the law of diminishing returns), you can predict that wikipedia will stop growing at about 3.5-4.5M articles – yet it doesn’t sound intuitive, because the world events (which want to be described) don’t stop then…
- Context Collapse – the academic term for missing the right audience, for example sending a private SMS to Twitter by accident
- Google+ circle types that people create, analysed
- Inner circle
- Structured groups (work, school, church)
- Interest groups (photography, sports)
- Catch-all for weak ties
- Edward Hall’s Proxemics (physical space from intimate->personal->social->public)
Susan Athey: Professor of Economics, Graduate School of Business, Stanford University, Presenting: The Internet and the News Media
- Research looking at the consumption of media differences between direct navigation and online aggregation (Google News, social networks)
- Interesting techniques & data sources: Bing web index, Twitter firehose, Wikipedia for article classification, Amazon Mechanical Turk for content categorisation
- Some topics clearly more consumed via social media (celebrities, individual people) and others direct sites (sports)
- Higher polarisation on liberal/conservative scale in social media (echo chamber effect with like-minded friends)
- We are going to see a lot of media organisations making strategic mistakes on short-term hard data (celebrities -> clicks -> ad $). You can not imagine a future where all available news in all available outputs is just celebrities, so the data about those does not answer strategic questions about what the rest will be and who will win there over the long term.
- Great data-centric companies, like Amazon, are regularly ignoring their data when setting prices.
Scott Klemmer: Associate Professor of Cognitive Science and Computer Science and Engineering, UCSD, Presenting: Design at Large
- http://hci.stanford.edu/research/assess/
- Research started on improving design processes in the age of parallel testing and experimentation, to overcome functional fixation – misconception that the way you are pursuing is the only way to solve a problem
- Parallel design process (sharing several versions in group vs one final design) created higher click through rates of resulting banners, higher user engagement, team cohesion, higher work satisfaction, etc
- Peer assessment of academic work: grade 5 random peers, one prof-graded benchmark for quality. Aggregated results close enough for pass/fail grade. Students report huge value in assessing other’s work as a learning experience (somewhat lower for self-assessment).
- Art & design schools have always had an ambient awareness of other’s creative process with the studio format. Computer science used to be the same in the era of computer classes.
- Working with bringing peer-assessment methods with Coursera to bring this back in the online age.
Eytan Bakshy: Data Scientist, Facebook, Presenting: Peer Effects and Social Product Design
- Social Influence in Social Advertising: Evidence from Field Experiments (Bakshy et al, 2012)
- Showing “Your friend(s) likes this” next to an add: every next friend [1..3] name shown increases clickthroughs 8-10%
- Showing “Your friend
likes this” vs “ like this” – latter has similar +10% effect - Open question: are strong ties actually more influential?
- Selection Effects in Online Sharing: Consequences for Peer Adoption (Taylor, Bakshy, Aral 2013)
- Advanced Internet Experimentation with PlanOut (paper submitted) – a new programming language to implement complex experiments quickly
- https://www.facebook.com/publications
Cristian Danescu-Niculescu-Mizil: Assistant Professor, Max Planck Institute SWS, Presenting: No Country for Old Members: User Lifecycle and Linguistic Change in Online Communities
- Slides: http://www.mpi-sws.org/~cristian/Linguistic_change.html
- A statistical framework for measuring linguistic change (how the norms, etiquette, etc are changing in a community following a new member joining)
- 10 yeas of BeerAdvocate, RateBeer, BreastCancer.org data (~15M forum posts)
- Ex: convention how to talk about smell: “…Aroma: …” – can plot the change over the year and compare with other conventions, like “S:” for smell.
- Other described changes in communities: re-tweet conventions, slang in hiphop forums…
- User-level change (Pennebaker 2007, etc): ex change from “I” to “us” over the years signals increased shared identity with the community
- Sociolinguistic models in the offline world (from 1966) have theorised very similar results gotten online, with some notable clarifications now
- It was presumed adult language stabilisation is achieved in 17 years. Online data shows it is actually relative, at 30% mark of users’ lifecycle in a community
- Post frequency used to be state of the art in online community churn prediction (Dror, etc). Linguistic change features (distance from community, language stability, adoption of lexical innovation) give up to 12% absolute (40% relative) improvement in prediction accuracy.